
Serverless GenAI Serving
AWS Serverless Architecture for Generative AI Applications
☁️
AWS Serverless Architecture for Generative AI Applications ☁️
What is Serverless Computing?
Serverless computing is a type cloud computing. You might ask what is cloud computing? Cloud computing is an alternative for the traditional “Bare Metal” on-prem physical computing, whereby the computational resources are provisioned to the user over the internet by a cloud service provider like AWS, for example. What makes serverless computing particularly interesting is that it is a manner of designing an execution system of an application where needed computational resources are on-demand and non-provisioned. This creates a more streamlined and cheaper execution system. In simpler terms, serverless computing is a way of utilizing computational resources flexibly without the need for dedicated servers, rather what is available can be used on-demand (1).
Other than “Bare Metal” computing, what are the other cloud computing options? There are three: Platform-as-a-Service (PaaS), Microservices computing (containers), and Virtual Machine-based computing (IaaS). Without getting into details of the other core cloud computing architectures, it is safe to say that the main advantage of serverless computing is that infrastructure is “abstracted” the most in the serverless model. Thus, leading to little-to-none infrastructure management and a much reduced execution cost since the execution is short-lived bursts of on-demand event-driven services with no provisioned resources (1).
What is Infrastructure Abstraction?
Infrastructure Abstraction (IA) is the trimming away of details pertaining to the underlying infrastructure used by a software from the developer or the user. Essentially, it is an unified interface to deal with all infrastructure elements such as storage, hardware, networks, and all other infra elements needed for an execution. This introduces a very high level of flexibility because an application can consistently run on-demand using this interface of abstracted infrastructure regardless of the underlying stack. This should directly mean scalability as well (2).
Through IA, we can introduce one new model: Function-as-a-Service (FaaS) which is a serverless computation model providing all the infrastructure needs for a developer’s logic (a function) to run in containers fully managed by the cloud service provider. This is the smallest building block of a serverless computation model whereby all application tasks are broken into singular functions performing a task given a specific event trigger (1).
An example of FaaS can be AWS Lambda Functions. AWS Lambda is defined as: “a compute service that runs code without the need to manage servers. Your code runs, scaling up and down automatically, with pay-per-use pricing.” It brings together all the concepts I discussed earlier into one instance smoothly: No need to manage servers, on-demand usage of computational resources, automatic scaling, cost efficiency, and flexibility. AWS Lambda can be seen as a way for large infrastructure abstraction (3).
Generative AI Application Elements
One of the main disadvantages of serverless computing is that it might not be useable for all use cases especially cases which require long-running processes or very low latency needs (1). Although these issues are tackled by recent developments so that you can have, for example, “durable lambda functions” which could have a duration of up to a year (3). So it makes sense to start out by evaluating what a Generative AI Application requires architecturally and only after that assess whether we can streamline it through the serverless FaaS model.
For the sake of simplicity lets focus on a question answering GenAI application and its requirements. In its most bare form, a this type of application will require the following:
User interface
Authentication and Monitoring
API layer for communication
Deployed Foundation Model
Storage
In my opinion, any generative AI application is derived from these elements. Without any one of those, the application seizes to be one. Conversational, Agentic, RAG, and any other variation of GenAI apps will only add to those but won’t remove any. This is because it follows the three-tier application model mentioned in AWS Whitepapers (4):
Presentation: What the user directly deals with. That is the user interface part of the application which allows the user to ask the question in the case of our basic question answering GenAI app.
Logic: What transforms user action to application functionality. That is represented by the elements 2:4, where the user is authenticated, their message communicated to the deployed foundation model, and sent the response back through the API layer.
Data: Where application stores media needed for functionality provision. That is the storage element.
In the case of conversational a dialogue management layer, along with conversation history storage will be added. In the case of RAG, a vector database will be added and an embedding model will be used along with search algorithms and so forth.
Now, we can ask the question. Can this be built using the serverless model? Absolutely, yes! To fully answer the question, I will be presenting a potential detailed architecture on Amazon Web Services but the same concepts can apply elsewhere.
Serverless Presentation
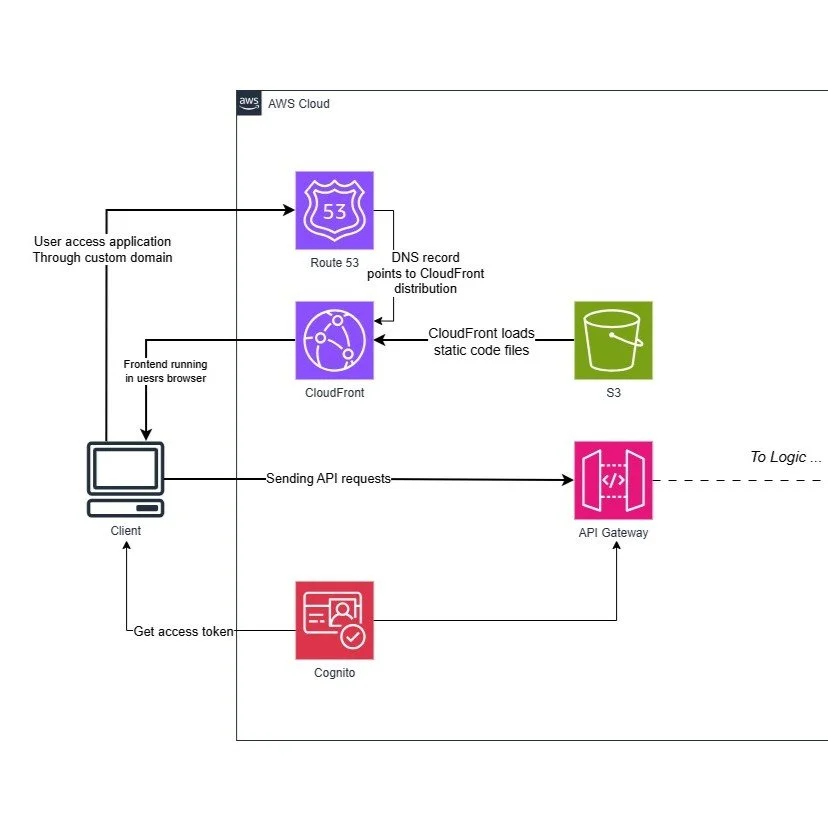
This is a serverless web application architecture proposed in the aforementioned AWS Whitepapers (4). The recipe is very simple yet very powerful. The frontend application is all cold files stored in AWS S3 which is suitable for object storage. The key player here is AWS CloudFront. CloudFront is a content delivery service which distributes the static content (stored in S3 in our case) to your users. How is it serverless? Because it delivers on-demand the content through a worldwide network of data centers called edge locations by routing the content to the location providing the lowest latency once a user requests the content (5). Therefore, there is no provisioned services dedicated to serving the frontend, rather it is event-driven and on-demand as characteristic of a serverless model.
The process goes as follows:
User requests access to a custom web domain.
Custom web domain is routed to CloudFront distribution using AWS Route 53, which is a DNS service mapping domain names to IP addresses and endpoints (6).
CloudFront downloads all the resources to the browser and starts to run from there (5).
User is authenticated and an access token is generated to enable APIs through AWS Cognito, which is a user directory for web and mobile app authentication and authorization (7).
The web application connects to the logic calling the APIs through AWS API Gateway, which is a service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs at any scale (8).
Serverless Logic and Data
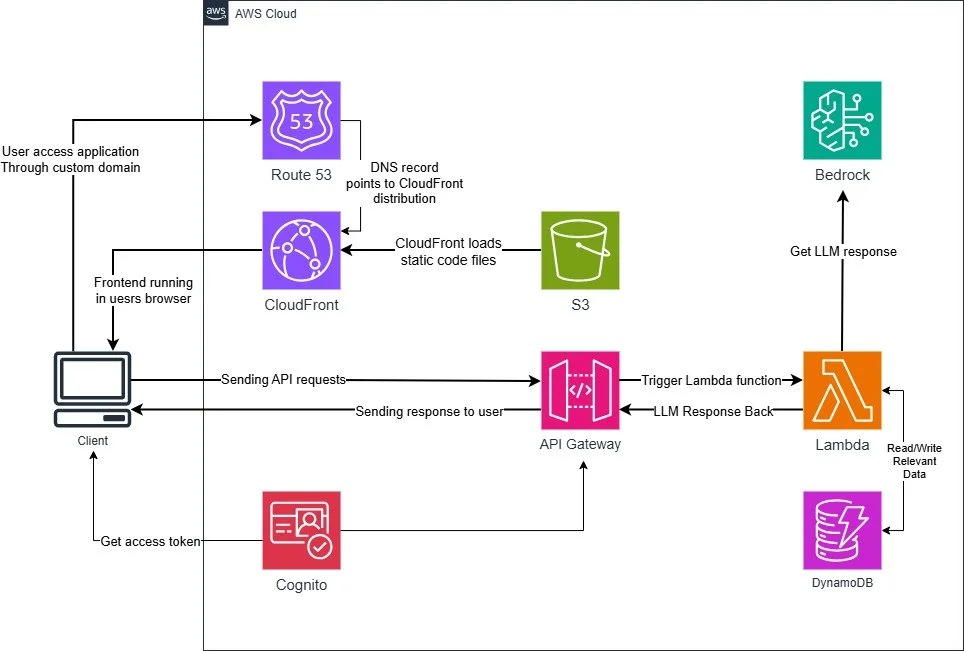
We covered the first magical serverless pair (CloudFront + S3), now the second and most important one will be covered: API Gateway + Lambda. This is a pair that technically can do almost anything. Together, they constitute an arm that can reach out very far with durability and efficiency with very little infrastructure management. Here is how it will go (9):
A prompt is submitted via the Amazon API Gateway endpoint, it is proxied to a Lambda function.
Lambda function logic uses boto3 SDK alongside an orchestration layer like LangChain to trigger response from Amazon Bedrock.
Lambda function can retrieve relevant message history to augment the prompt and write the new Q&A pair in a serverless database like DynamoDB or others (know more about serverless databases here and here).
Finally, it sends the response back to user through the designated API Gateway endpoint.
The serverless FaaS provides event-driven compute through Lambda which is appropriate for generative AI applications given that they require on-demand compute-intensive tasks (9).
Serverless Model Deployment
A key element in this diagram has not been discussed at all, which is Amazon Bedrock. This is where the foundation models are deployed and exposed for consumption. Let’s dive a little deeper into Bedrock and what makes it serverless. Bedrock is a service managed by AWS aimed at providing “high-performing foundation models (FMs) from leading AI companies and Amazon available for your use through a unified API” (10).
Essentially, Bedrock enables on-demand access to foundation models with no infra management through the boto3 SDK among others. This is what makes it serverless! Alongside this, it has all right tools for management of the generative AI application like: model configuration, fine-tuning, adding guardrails, building knowledge bases, and more (9)(10).
Scalability
To conclude this blog, I want to discuss how scalable this is and what can be some of the drawbacks. The key services here are: API Gateway, Lambda, and Bedrock. They are all pay-per-request on-demand services, and can handle thousands of requests concurrently. API Gateway and Bedrock are very scalable and are still used by other cloud computing models. The question of scalability has to be directed at Lambda specifically.
Lambda is designed to automatically scale with usage but there are some hard quotas designed to help maintain other customers’ workloads since there is no provisioned dedicated infrastructure. In Lambda, “code can run for up to 15 minutes in a single invocation and a single function can use up to 10,240 MB of memory”. Internally, Lambda has automatic scaling capability with a limit of 1,000 concurrent executions per 10 seconds. Each execution environment allocated to the function can handle 10 requests. So a Lambda function can handle 10,000 requests in 10 seconds. Can the concurrency limit change? Yes, it can go up to tens of thousands (11)(12). That level of scalability is offered with no infrastructure management, and that is the beauty of serverless computing.
This is scaling up from within lambda itself, but what happens if there is chat session with a foundation model that is taking more than the maximum 900 seconds (15 min) function timeout? Well, you can switch to Lambda durable functions which enable building “resilient multi-step applications and AI workflows that can execute for up to one year while maintaining reliable progress despite interruptions”. Essentially, these functions are just a checkpoint-based series execution of traditional Lambda functions hence enabling the user to pay for active execution time (13). You can check the diagram in (13) to get a better view of this. The orchestration of consecutive Lambda functions can be done in a multitude of ways by the architect, as well. This can be done using AWS Step Functions, SQS, SNS, or even from within the running to-be-timed-out Lambda itself.
Cold Start and Cost-at-scale
Serverless computing through Lambda as FaaS can have many issues but the main two issues seem to be cold starts and cost-at-scale. What is a “cold start”? It is the process of initiating the environment within which the piece of logic (i.e. the function) will be running. It involves: downloading the code and starting the new execution environment. They typically occur in under 1% of invocations and take from 100 milliseconds to 1 second, which can be noticeable in a conversational UX (14).
The solutions for the issue of cold starts involve either minimizing environment initialization time to the lowest possible through having minimal packages installed and so on, or through provisioned concurrency, which is the pre-initialization of concurrent functions expected to handle the in-flight requests our application typically deals with at a given time (15). It is important to note, that cold starts are said to be more prone to occurring in development and testing environments because of infrequent usage (14). Another thing that helps with the cold starts issue is to avoid placing Lambda in a VPC, because that will consume seconds to set up ENI. That is why, a public serverless database would be best in this scenario so the statelessness of the Lambda function can be overcome with having access to DynamoDB, for example, without adding networking overhead.
When it comes to cost, serverless models are researched to offer up to 57% cost savings from the total cost of ownership (16). But in the case of steady and high-volume traffic cost can spike and other options like IaaS, PaaS, or Microservices may seem to be better options where dedicated hardware is provisioned to handle the needed traffic. Ultimately, that is the decision of the developer/architect, but here are some ways to battle spikes in cost for the FaaS model that we have built and more can be found in (16). The options are as follows:
Filtering incoming requests and providing cached responses in the cases of greetings and gratitude.
Selecting suitable size, timeout, and overall configuration for the Lambda function.
Avoiding the over-provision of concurrency for the Lambda function.
Those alongside others are means to ensure Lambda running cost is optimized (16). In conclusion, serverless architecture for serving foundation models is very feasible and might be ideal for generative AI applications across the board even agentic ones. It just needs the right development, testing, and most of all “architecting” which are all facilitated by the serverless model given that it costs much less time and money in both: initial development, and ongoing infrastructure management and maintenance (16).
Sources
1) “What is serverless Computing?”, Google Cloud. Link: https://cloud.google.com/discover/what-is-serverless-computing
2) “Infrastructre Abstraction”, Dermio. Link: https://www.dremio.com/wiki/infrastructure-abstraction/
3) AWS Lambda Documentation. Link: https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
4) AWS Whitepapers: Serverless Multi Tier Architectures with Amazon API Gateway and AWS Lambda. Link: https://docs.aws.amazon.com/whitepapers/latest/serverless-multi-tier-architectures-api-gateway-lambda/introduction.html
5) AWS CloudFront Documentation. Link: https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/Introduction.html
6) AWS Route 53 Documentation. Link: https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/Welcome.html
7) AWS Cognito Documentation. Link: https://docs.aws.amazon.com/cognito/latest/developerguide/cognito-user-pools.html
8) AWS API Gateway Documentation. Link: https://docs.aws.amazon.com/apigateway/latest/developerguide/welcome.html
9) AWS Compute Blog: Building a serverless document chat with AWS Lambda and Amazon Bedrock. Link: https://aws.amazon.com/blogs/compute/building-a-serverless-document-chat-with-aws-lambda-and-amazon-bedrock/
10) Amazon Bedrock Documentation. Link: https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html
11) Lambda quotas. Link: https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-limits.html
12) Lambda scaling behaviour. Link: https://docs.aws.amazon.com/lambda/latest/dg/scaling-behavior.html
13) Lambda durable functions. Link: https://docs.aws.amazon.com/lambda/latest/dg/durable-functions.html
14) Understanding the Lambda execution environment lifecycle: Cold starts and latency. Link: https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime-environment.html#cold-start-latency
15) Configuring provisioned concurrency for a function. Link: https://docs.aws.amazon.com/lambda/latest/dg/provisioned-concurrency.html
16) Understanding techniques to reduce AWS Lambda costs in serverless applications. Link: https://aws.amazon.com/blogs/compute/understanding-techniques-to-reduce-aws-lambda-costs-in-serverless-applications/